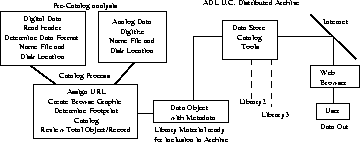


The following figure is a very generalized model of how data would flow into the system and be accessed by Internet users. The contents of each box in Figure 1 will be talked about in the context of very generalized processes so that a series of specifications can be constructed for describing individual archive hardware, software and personnel requirements.
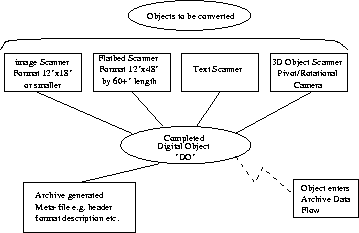
If the library item was originally in analog form, it would have to be scanned or in someway converted to a digital object before starting the process into the library. A very generalized digitizing flow diagram follows where various types of scanner technologies, hooked to a network of computer workstations, and supported by trained staff would provide this step in the digital archiving process.
The standards used in the various processes necessary for end-to-end operations are very important. Areas where standards are required are in communications (e.g., network protocols); data management (e.g., metadata description, data format and storage, database query protocols etc.); production (e.g., scanning, header generation, documentation etc.); and systems (e.g., software, operating systems, etc.). These and others must work in harmony if the total distributed system is to work properly. From the archive perspective, some of these standards and protocols are more important than others and are talked about in more detail below.
ADL, for example, is working on a metadata model that incorporates two major metadata standards, the Federal Geographic Data Committee metadata standard, (FGDC), and the library MARC cataloging standard. These two data description standards have been combined and are currently being used by the ADL testbed. The ADL metadata standard is not complete and must allow for growth and change due to the dynamic nature of spatially indexable data and the continuous emergence of new media.
Standards for scanning, data storage, and creating ADL tools such as the ADL Gazetteer are being researched and will be tested within the UC Prototypes.
Digital storage for the operational library is a complex issue, first because of a single archive's needs for management and control of their own data collections and second due to expanding user expectations. ADL is being viewed as a distributed system; following this philosophy, the physical storage of data most likely will be distributed. Several storage paradigms are available: first, data storage for any archive node may be totally local, totally remote (e.g., using mass storage at ADL or a super-computer site), or a combination of both. Second, data storage may be shared across nodes (e.g., parts of a dataset may reside at several sites but when combined, all segments are complementary), or third, datasets might reside at several nodes. The third option might be employed because of network considerations, or to offer dataset redundancy.
Storage in an operational environment must provide at least two services; the first is to the archivist populating the store; the second is to the user who seeks access to the data. Each service has its own requirements: the archivist might have to preprocess the data as part of the ingest function, e.g., do a wavelet transform or compress the data. The user seeks fast access. ADL is conducting several research sub-projects centered on data delivery. These include progressive delivery of a digital file using wavelet technology; providing sub-setting of a dataset so that only a small user-defined area is retrieved from the larger dataset; providing multiple representations of the same dataset at different resolutions, e.g., the complete file might be 1 gigabyte in size so several other reduced resolution files of smaller size would be made available for downloading. These continue to be active research areas and the ideal solution may not be available to the general user for some time. Until a comprehensive solution is implemented, FTP and mail may be the fastest method of retrieving very large digital files.
Several staffing models are being explored depending on archive resources and level of commitment. Since several new services will be required to operate the library, new or reassigned staff are being committed for scanning, systems management, and user services e.g., applications required to integrate archive data into desktop software, provide digital file conversion between archive storage areas etc. An alternative might be the centralization of certain processes such as scanning, dataset loading, cataloging maintenance, etc. Each alternative will be reviewed in detail while paying special attention to such things as intra-campus network speeds and data security.
Training of archive personnel would be done by several factions; hardware including networking, software for working with ADL, and applications software. Each training group would be responsible for development of their own programs but would be coordinated by ADL management staff.
In the sprit of cooperation, examples of datasets thought to be important to various U.C. library's follow.