


Membership: Su (leader), Agrawal, El Abbadi, Freeston, Frew, Singh, Smith, Cheng, Dolin, Kothuri, Prabhakar, Wu
Mission Statement of Team: The Team's research is focused on a number of issues pertaining to the architecture of digital libraries including resource discovery, extensible data store, and the implications of building a geographically referenced database. In relation to geographically referenced databases, issues under investigation include multi-dimensional indexing, data placement, tertiary storage, content-based retrieval, and performance tuning.
Research activities over the last year
Having established the superiority of the newly proposed schemes for range queries on two-dimensional data, the team explored extensions to other data sets and query patterns. Two extensions were made: 1) Declustering for multidimensional range queries and 2) declustering for nearest-neighbor queries. The schemes which were earlier found to give very good performance for two-dimensional range queries were also shown to have very good performance for the other two query types. The cyclic schemes are found to be the most stable schemes, giving the best performance in a wide variety of settings. The results for nearest-neighbor queries will appear in SPAA '98, and the results for multidimensional range queries are currently submitted for consideration.
The team has since built a small prototype of the proposed Pharos architecture. In order to accomplish this we installed the information retrieval system, LSI (Latent Semantic Indexing) Package from Bellcore. This software was used to aid in the automatic classification of information content of sources under Pharos. In addition, we used UCSB's library catalog data (approximately 2 million MARC records). These records were used as sample data (a training set) for Pharos development.
This prototype enables searching
newsgroups (which are taken as collections by Pharos). We
made the system available on the Web for
general use and testing
(http://pharos.alexandria.ucsb.edu/demos/).
A full description of this system appeared in the January, 1998
issue of D-Lib Magazine (http://www.dlib.org).
We have conducted an analysis of of the retrieval mechanism using the real newsgroup data and found that, assuming that the classification is basically sound, the query result accuracy is acceptable.
The principle architect of this part of the group, Ron Dolin, will be completing his Ph.D. by June, 1998.
In our earlier research, we showed that the lower bound on range
query time complexity is 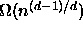 for n
d-dimensional data items. This lower bound holds for all
non-replicating tree structures (i.e., tree structures that do not
replicate data items). The k-d tree of Bentley achieved this
complexity in static environments. For dynamic environments, where
data items may be inserted and deleted, we proposed a new data
structure, called the O-tree (`O' indicating optimality), that
achieves the proposed lower bound. Insertions and deletions are
supported in
for n
d-dimensional data items. This lower bound holds for all
non-replicating tree structures (i.e., tree structures that do not
replicate data items). The k-d tree of Bentley achieved this
complexity in static environments. For dynamic environments, where
data items may be inserted and deleted, we proposed a new data
structure, called the O-tree (`O' indicating optimality), that
achieves the proposed lower bound. Insertions and deletions are
supported in 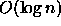 amortized time. This structure improves the
query complexity of divided k-d tree, the best known non-replicating
structure for dynamic environments.
amortized time. This structure improves the
query complexity of divided k-d tree, the best known non-replicating
structure for dynamic environments.
Next, we examined how to improve the performance of multi-dimensional
structures in the presence of concurrent operations by multiple users.
Multi-dimensional structures such as R -trees differ from their
uni-dimensional counterparts in the following aspects: (1) index
regions in the tree may be modified during ordinary insert and delete
operations, and (2) node splits during inserts are quite expensive.
Both these characteristics may lead to reduced concurrency of update
and query operations. The Team first developed a new technique for
efficiently handling index region modifications. Then, the Team
extended it to reduce/eliminate query blocking overheads during
node-splits. Experiments on texture image data on a shared-memory
multi-processor indicated that these protocols achieve up to 2 times
higher throughput than existing ones, and scale well with the number
of concurrent users.
-trees differ from their
uni-dimensional counterparts in the following aspects: (1) index
regions in the tree may be modified during ordinary insert and delete
operations, and (2) node splits during inserts are quite expensive.
Both these characteristics may lead to reduced concurrency of update
and query operations. The Team first developed a new technique for
efficiently handling index region modifications. Then, the Team
extended it to reduce/eliminate query blocking overheads during
node-splits. Experiments on texture image data on a shared-memory
multi-processor indicated that these protocols achieve up to 2 times
higher throughput than existing ones, and scale well with the number
of concurrent users.
Finally, the Team examined image retrieval based on content. Research in the previous year focussed on comparison of the quality of dimensionality reduction using SVD and DFT. The Team observed that SVD-based dimensionality reduction performed better results than one using DFT. Unfortunately, SVD-based dimensionality reduction was applicable only to static image databases, where all the data is known a priori. The Team proposed novel techniques for efficiently performing SVD-based dimensionality-reduction in dynamic databases. The technique involved recomputing the SVD periodically using an aggregate data set instead of the entire database. This resulted in a reduction of the associated computation overheads by up to two orders of magnitude. The error due to approximation in SVD computation is less than 3%. These results were obtained from experiments on two real image datasets: one with 144K 256-dimensional color histograms, another with 26K 48-dimensional texture features.
StratOSphere provides a general mechanism for distributing processing across different hosts. It accomplishes this through the following means:
One basic idea is to pre-compute queries, store and index the answers, which are called ``materialized views''. When a user query comes, the query is rewritten (in a way transparent to the user) so that the materialized views are used instead of performing joins. A set of systematic experiments of materialized views have been conducted in both Sybase and Illustra DBMSs using ADL gazetteer database. In addition to the confirmation that materialized views give a significant query performance gain, the experiments focused on the scalability and applicability issues of the materialized view approach. In particular, queries with different properties were tested. These properties include join ratios, table numbers and sizes, answer sizes etc. The results show a large range of speedups (from 1.5 times faster to nearly 3000 times) due to those different properties.
But with materialized views, too many queries are to be pre-computed and ad hoc queries are unpredictable. The main research progress the team has achieved in this task is a novel technique for selecting queries to be materialized. This technique is based on several observations related to ER diagram and the ADL user query logs. The following are the main contributions of this technique:
Principal Investigators: Michael Freeston, Terence Smith
Project Award Information
Name of project: A New Generic Indexing Technology for Digital
Library Support
Duration: 3 years
Current award year: 1
Project Summary
Most of computing reduces to sorting and searching, so one would
expect that the study of indexing methods would be constantly at
the forefront of research efforts in computer science. And yet the
indexing technology on which the whole of the database industry
relies the B-tree has not changed for 25 years. We contend that this
technology is inadequate and inappropriate for the kinds of
application which it is now required to support, and that it is
time for a radically new approach. In its place we propose a new,
generic indexing technology founded on multi-dimensional indexing.
The theoretical and practical basis for this technology has been
developed by the project PI in a research effort extending over
the past ten years, culminating recently in a number of key
theoretical advances. The most important of these is a general
solution of the n-dimensional B-tree problem [Fre95] - a problem
which McCreight (co-inventor of the B-tree) has described as
one of the persistent puzzles of computer science. The challenge
now is to test these advances in a practical implementation
of the whole technology.
The philosophy behind the approach is in direct contrast to the current trend towards data blades or data cartridges i.e. the idea of plugging in a different index method for each data type. By studying the underlying principles of indexing techniques, we have been able to extend the worst-case performance characteristics of the B-tree to a method of indexing any data structures which can be expressed as directed graphs. The resulting technology thus has a very wide scope, ranging from conventional relations to logic clauses, and from spatial object vectors to pictorial image rasters. The central objective of the project is to develop support for all these areas within one integrated, generic indexing system. The aim is to maximize functionality and internal compatibility while maintaining low software complexity. The application focus is the Alexandria Digital Library [ADL98] project at the University of California, Santa Barbara. At present, ADL relies for its indexing support on existing commercial database systems. However, the indexing functionalities required by ADL are well beyond those which existing systems support. The new project is running in parallel with ADL, monitoring its indexing needs and devising solutions within the new technology. Because of the close collaboration between ADL and a number of leading commercial database suppliers, the new project aims to use these established channels of communication to convey the ideas and results generated in the project directly into the commercial database sector.
Goals, Objectives, and Targeted Activities
We have already achieved our first milestone: an implementation
of an enhanced form of point and spatial BANG indexing [Fre87, Fre96]
using a conventional balanced tree structure. We are currently
engaged in comparative benchmark tests against the B-tree and the
R*-tree. We have also developed a first version of an interactive
display and analysis tool designed to aid the study of indexing
functionality and performance. The next target is to produce a first
full implementation of a BV-tree [Fre95]. This has two principal
objectives: first, to determine the level of software complexity and
algorithmic complexity of the implementation algorithms; and second,
to confirm the predicted performance characteristics in practice. By
the end of the first year, we aim to have constructed the foundation
of the full indexing technology: enhanced BANG indexing supported by
a BV-tree structure.
Indication of Success
It is too early in the life of the project to assess the success of
its primary objectives. There have, however, already been a number
of interesting and unforeseen developments arising from the synergy
between the project and the Alexandria Digital Library. Here are
two examples:
1. Support for scaleable queries
ADL is a library of spatially referenced information, its collection
consisting primarily of maps, aerial photographs and satellite remote
sensing images. Users can search the library by specifying relevant
object types in a defined geographical area. Very often, they would
like to restrict the results of queries to a scale proportional to
the geographical scale of the query region. For example, a query of
political boundaries within the whole American continent might be
limited to national rather than state or county boundaries.
Or a population query might return only centers of population exceeding 100,000 people. This has led us into an unexpected new field of study, mixing spatial and non-spatial components of multi-dimensional indexing. As far as we are aware, there is no available commercial database support for these kinds of scaleable queries and, until now, there has been little or no research on the problem.
2. Text retrieval
ADL requires the closest possible integration of text retrieval and
database query support. We are therefore making a new assault on this
long-standing problem, which still lacks a fully satisfactory solution.
The surprise is that the new indexing technology has properties, not
previously considered, which seem particularly suited to string
processing. In fact it seems that there is a similar relationship between
the new technique and Pat (Patricia) trees (as used in the Oxford English
Dictionary indexing project) as there is between the new technique and
quad-trees i.e. the former subsumes the latter.
These examples have a wider significance: they support the claim that, by the nature of its theoretical foundation, the new indexing technology can support any structure expressible as a tree, and hence does indeed merit the term generic. One further point of interest: the index visualization tool has proved to have an unexpected value as a software debugging tool: programming errors which produce no obvious faults in behaviour or numerical results often become immediately evident in the visualization.
Project Impact and Output
The importance of the project to the long-term performance and
scalability of ADL has been recognized in the current assignment of two
ADL-funded RAs to the project, in addition to the single RA funded
directly. Considerable interest has also already been shown by the
vendors of the two main databases - Oracle and Informix - currently
supporting ADL. We have recently decided to build some
experimental Informix datablades with the new technology.
Project References

Area Background
Although there is always a session devoted to indexing techniques at
the major database conferences, it is sometimes said we should stop
doing research into this area as we have plenty of good indexing
techniques already. In fact this is not the case. There have been
many design proposals, but very few have stood the test of time. As
pointed out in the project summary above, the database industry still
relies on an indexing method devised over twenty-five years ago. And
yet efficient indexing is of immense importance: just imagine how
much processing time might be saved in the US in one year if the B-trees
in every database system could be replaced with something, say,
5% more efficient. It is also sometimes said that indexing techniques
are now about as good as they are going to get - that because we have
relied on the B-tree for so long, there probably isn't anything better.
This is nonsense. Just try recalling any incident from any moment in
your life, however long ago. You will be able to retrieve a complete
visualization in your mind within a fraction of a second - certainly
within the time of 50 disk accesses at most. Current storage and
indexing methods don't come anywhere near such performance.
This example illustrates a further point: that multi-media is not just changing the content of database systems, it is blurring the boundaries with other areas of computer science: image recognition, for example. For this reason, the study of indexing methods today is a wider, more interesting and much more challenging field than ever before. It is ultimately about persistence and scaleability: if your system is a main-memory toy, you don't need to think much about indexing. But once you need to rely on slow secondary storage for persistent memory, and to store and access objects in a time which doesn't increase linearly or worse with the number of objects, and to garbage-collect everything perfectly so that non-stop operation is possible, then you need to start studying indexing techniques.
Area References

Potential Related Projects
As pointed out in the project summary, the scope of the indexing
technology under development in this project is very wide. Potential
applications which we have already identified for study include:
the replacement of 'conventional' relational database indexing by
multi-dimensional indexing; complex structure indexing in
object-oriented databases; spatial indexing in GIS systems (including
large-scale persistent quad-trees); substring indexing in text retrieval
systems; constraint database indexing; multiple-resolution image
indexing; image feature indexing; and logic clause indexing in
large-scale deductive database systems.
Executive Summary
The Alexandria Digital Library (ADL) is a library of geo-spatially
referenced information. Efficient storage, access and manipulation of
representations of objects in terms of their spatial location and/or
their spatial extent is therefore a fundamentally important
functionality of the underlying system(s) supporting the library.
The policy so far has been to rely on commercially available database
systems to provide this functionality. Unfortunately, however, all
those available to the project have so far been found severely lacking
in several respects, and we are not aware of any alternative system
which offers any obviously superior technology.
In fairness to the vendors, it should be pointed out that it is only
during the lifetime of the ADL project that the major database
companies have begun to add spatial data handling facilities to their
products. ADL has thus been a valuable testbed for the vendors, which
has been the major motivation for the support which ADL has received
from them. The downside for ADL has been development delays and
instability of the implementations of the new products.
We report here on three specific designs:
Of these, only Illustra has so far actually been incorporated into the library to provide spatial indexing facilities. Oracle provides all other database support. The reason for this combination is partly historical and partly technical. Illustra was the first general-purpose database system to offer spatial data handling and, whatever other virtues Illustra may have, this seems to have been the major factor in its early commercial success. For ADL the initial choice was simple, since there was no alternative on offer. Unfortunately the product was unstable, and simply didn't work for large data sets. Although this was eventually fixed, all hope of any serious further development of Illustra was lost with the acquisition of Illustra by Informix. And, as anticipated at the time, the birth of a substitute in the form of Informix Universal Server has been long and painful. The story at Oracle has not been much better. Oracle 7MD (MD = Multi-Dimension) was announced early in 1996, and apparently withdrawn almost immediately. The Canadian group responsible for its development was disbanded, and a new effort begun to incorporate some spatial data handling capabilities into Oracle 7.3. This emerged in late 1996 as Oracle Spatial Data Option. It retains the basic design of Oracle 7MD, but claims to be better integrated into the whole system. ESRI's Spatial Data Engine is, in the tradition of ESRI, not a stand-alone database product, but relies on the support of an underlying relational database system. Implementations are available for both Oracle and Informix.
Overall Conclusion
For those who would rather skip the technical arguments, we give our
main conclusions below:
We believe that the basis of Oracle's approach has great potential,
but has not been sufficiently recognized or exploited by Oracle
themselves. The design has clearly been severely restricted by the
need to implement it within the limitations of the existing database
system: specifically, within a strict relational data model and
without any additional indexing methods. The result is a simulator:
evidently a stop-gap which can only be filled by a fundamental system
redesign. The transition to the object-relational model in Oracle
version 8 provides an opportunity to do this, although so far Oracle
8 does not seem to offer any advance in its spatial data handling
capabilities. We consider that, without the introduction of radical
new spatial indexing methods, the advantages of the object-relational
model will not be enough to beat off the competition. The Spatial
Data Blade which Informix has inherited from Illustra relies on an
indexing technique - the R*-tree - which, along with its predecessor,
the R-tree, has remained the favorite spatial access method among
academics for over ten years - perhaps because it is relatively
simple and attempts to generalize the familiar B-tree to n dimensions.
Illustra's strength was that the whole database system was built from scratch, and so was not constricted to conform to an existing design. The Data Blade concept was specifically developed to try to avoid such constrictions, by making it possible to plug in new indexing methods at any time. This concept is very appealing, but we are not convinced that the optimizer can in general utilize such new methods effectively without significant modification - which would effectively amount to a major system rewrite. We nevertheless rate the Illustra/Informix approach to spatial data handling higher than that of Oracle for the foreseeable future. ESRI's Spatial Data Engine (SDE) is also a simulator which sits on top of a standard relational database system, but supports its spatial indexing in a separate subsystem (reminiscent of the standard ARC_INFO architecture). This incurs severe performance penalties, and requires the user to formulate the separate spatial and non-spatial components of a complete spatial query. From ESRI users' point of view, this at least has the advantage that the spatial data and the feature data can be stored in a standard relational database such as Informix or Oracle. The performance, however cannot possibly compare with that of either Oracle SDO or the Informix R-tree.
An incisive comparison of Oracle SDO and ESRI SDE: ``Limitations of
Spatial Simulators for Relational DBMSs'' by Michael Stonebraker can
be found at:
http://www.informix.com/informix/corpinfo/zines/whiteidx.htm.
It must be borne in mind that this document purports to show the
advantages of the Informix solution above all others, but the case
against the Oracle and ESRI approaches is very convincing. In our own
assessment below, we have been able to balance the argument a little
by including our reservations about the R*-tree. Our own indexing
research over the past ten years throws a different light on these
comparisons. The author developed BANG indexing ten years ago which,
like Oracle SDO, uses Peano codes to delineate data space partitions.
Unlike Oracle SDO however, it is able to adapt these partitions
gracefully to any data distribution, thus generalizing the
performance characteristics of a B-tree to n-dimensions. And despite
the claims of Informix, an independent study as long ago as 1989
concluded that the performance of BANG indexing for both points and
extended spatial objects was never worse than that of R-trees, and for
containment queries was over an order of magnitude faster! Our own
current comparative studies on BANG and R* tree indexing show that an
R*-tree is larger, and takes between 3 and 4 times longer to build
than an equivalent BANG tree. A new NSF funded project to evaluate
and develop this technology further has just begun at UCSB. A web
site describing the technology in detail, and with continual updates
reporting results obtained by the project, will be made publicly
accessible by the end of November 1997.
A Detailed Comparison
Preliminaries
Oracle Spatial Data Option (SDO) is implemented in Oracle 7.3 in
terms of a pure relational model. This fact alone may be considered
by many to disqualify the design from serious consideration, because
of a widely held belief that GIS applications cannot be efficiently
supported within a pure (i.e. fully normalized) relational model.
This is certainly the generally advanced explanation for the
schism between the GIS world and the mainstream business
database world in the early seventies. The argument is that the
complex geometric object types employed everywhere in GIS, such as
line chains and polygons, cannot be efficiently represented in the
relational model. Nevertheless we don't find this argument entirely
convincing. The evidence clearly shows that the root cause of the
problem is simply that relational database systems were not --
and are still not -- designed to optimize the performance of GIS
applications. This requires specific support of four kinds:
As an example of the issues involved, let us consider the
representation of polygons. In a fully normalized relational
model, a polygon must be represented by tuples in two relations:
a) a polygon relation: a single tuple which contains a set of
``feature'' (i.e. non-spatial) attributes, plus
b) a vertex relation: a set of tuples, each representing the
coordinates of a single vertex of the polygon.
A unique polygon identifier of some kind must also be stored in
each of these tuples, so that the relationship between them
(i.e. vertex of polygon x) can be established. If the polygons
are non-convex then, since no physical or logical order of the
tuples of an unindexed relation is guaranteed, a sequence number
must also be assigned to each vertex tuple in order to define
the polygon uniquely. (Even for convex polygons, this would
anyway be necessary for efficiency reasons). In GIS applications,
it is not unusual for such a polygon to contain several hundreds,
or even thousands of vertices. Let's now consider the efficiency
of this representation for retrieval operations, starting with
non-spatial queries i.e. queries which contain no explicit
constraint(s) on the spatial extent of the result. Suppose the
set of polygons represents county boundaries, and we want to
highlight a single county on a display map by specifying
the name of the county. Assuming that county_name is a feature
attribute of the polygon relation, we can search this relation
for the polygon identifier associated with the county name.
The vertices of the polygon, together with their sequence
numbers, can then be found in the vertex relation, by searching
for tuples containing this polygon identifier. The geometry
of the polygon is now completely defined, and the county can
be drawn on the display. This is an almost trivially simple
search and retrieval operation, but there are two requirements
which must be fulfilled to ensure its efficient execution:
a) both relations must be indexed: the polygon relation on
county_name, and the vertex relation on polygon_identifier.
(An index on sequence_number within polygon_identifier is
actually more practical, because there is then no need to sort
the set of retrieved vertices);
b) the tuples in the vertex relation must be physically
clustered in index order.
The first of these requirements is obvious, but the second
is frequently overlooked, and may not even be supported by
the system. We assume for the moment that all dynamic ordered,
indexes are supported by B-trees, which is almost universally
the case among the major commercial database systems. We
also assume that:
1) physical clustering is available as an option, such that
the leaf nodes of the index point to data pages within which
tuples are physically stored in index order;
2) when data is physically clustered, data pages are directly
linked together in index order.
In this case, once the first vertex specified by a polygon
identifier has been retrieved, then the others can be retrieved
efficiently simply by passing through a linked list of data
pages until a non-matching polygon identifier is found. The
total number of index and data pages accessed is then equal
to the height of the index tree plus the total number of
data pages traversed.
Digging a little deeper, let's assume a typical data page size of 8K bytes; polygons containing an average of 1000 vertices (not unusual); and a vertex tuple representation consisting of four 4-byte fields: two vertex coordinates; a polygon identifier and a vertex sequence number. Then an average polygon will occupy 2 data pages of the vertex relation. Assuming a typical height of 3 for the index tree (not including the data nodes) of both the polygon and vertex relations, the total access cost will thus be: 3+1+3+2=9 page accesses.
If direct data page linking is not supported then, in general,
it will be necessary to traverse more index pages. In the worst
case, the full height of the tree has to be traversed twice in
order to reach two sequential data pages, so that the
worst-case page access cost of our average polygon becomes:
3+1+5+2=11 (N.B. the root page is only counted once, because
it is visited twice, and we assume at least some elementary
page caching). [In fact, although we have never seen this point
discussed, the linking of data pages has little practical effect
on the efficiency of range queries which visit more than a few data
pages, as a moment's reflection will show. Suppose, in the example
above, the fan-out ratio of the index nodes is O(100). Then
although retrieval of the first polygon requires 11 page
accesses, all the remaining polygons in the next  99 data
pages can be retrieved by revisiting their common parent index
node -- which, with elementary caching, incurs no additional
disk access overhead at all.] Let us now consider the
non-clustered case, where each tuple is randomly located in a
heap of data pages, independent of the index tree structure.
Each entry in the index leaf nodes now points to an individual
tuple location (page and offset) in the heap. Thus the retrieval
of each tuple will normally require one page access and, in our
polygon example, the retrieval of a single, average polygon now
requires 1000 data page accesses! Now suppose that the whole
specification of the polygons, including their vertices, is
stored instead in a nested (i.e. un-normalized) relation or
set of equivalent complex object instances. The only basic difference
between this representation and that of the physically
clustered normalized relational representation is that it is
no longer necessary to store the polygon identifier and the
vertex sequence identifier with each pair of vertex coordinates,
since the vertex order can be implied by the physical
storage order. In our example, this results in a space
saving of 50%, so that an average (i.e. 1000 vertex) polygon
now occupies a single data page. The total access cost
to our average polygon thus becomes: 3+1=4 page accesses.
99 data
pages can be retrieved by revisiting their common parent index
node -- which, with elementary caching, incurs no additional
disk access overhead at all.] Let us now consider the
non-clustered case, where each tuple is randomly located in a
heap of data pages, independent of the index tree structure.
Each entry in the index leaf nodes now points to an individual
tuple location (page and offset) in the heap. Thus the retrieval
of each tuple will normally require one page access and, in our
polygon example, the retrieval of a single, average polygon now
requires 1000 data page accesses! Now suppose that the whole
specification of the polygons, including their vertices, is
stored instead in a nested (i.e. un-normalized) relation or
set of equivalent complex object instances. The only basic difference
between this representation and that of the physically
clustered normalized relational representation is that it is
no longer necessary to store the polygon identifier and the
vertex sequence identifier with each pair of vertex coordinates,
since the vertex order can be implied by the physical
storage order. In our example, this results in a space
saving of 50%, so that an average (i.e. 1000 vertex) polygon
now occupies a single data page. The total access cost
to our average polygon thus becomes: 3+1=4 page accesses.
In summary, access to the nested or complex object representation in this example is over twice as fast as to the clustered implementation of the normalized relational model. This is generally true for all objects occupying less than one or two pages. But the implementation of physical clustering in the normalized representation has a far more significant effect on access efficiency than the adoption of a complex object representation. This conclusion holds equally well for spatial queries, assuming the conventional two-stage approach to spatial querying: in the primary filter stage, spatial extents such as polygons are approximated by simpler object covers - usually either minimum bounding boxes, or sets of tiles. This approximation makes it much easier to test if, for example, an object lies within a specified query window, but may yield some false drops i.e. objects whose actual external boundary does not lie within the query window. Clearly, if the object's minimum bounding box lies completely within the window, then the object which it covers must also lie completely within the window. If, however, the minimum bounding box intersects the window boundary, then a secondary filter stage is necessary to test the precise spatial relationship between the query window and the actual external boundary of the object. This is generally a much more computationally intensive operation. The point to note here is that the level of performance of the whole query depends on physical clustering in just the same way as for non-spatial queries. The above considerations should be borne in mind when evaluating claims that the transition from relational to object-relational database architecture will lead to a major improvement in performance. We conclude that an efficient implementation has more to do with good design and appropriate index structures than with the choice of data model. We are therefore back to where we began: effective support for spatial data applications depends on the provision of appropriate index mechanisms and spatial operators within the kernel of the database system, and an optimizer which can take advantage of them. Unfortunately, this requirement faces database vendors with a daunting prospect: any changes to the kernel of a major commercial database system carry with them tremendous risks. Any malfunction resulting from the change may affect every application of every user. So database vendors do not lightly make major changes to their database kernels. This almost certainly accounts for the fact that Oracle has opted to provide support for spatial applications through a simulator. By this means, apart from the addition of a topological comparison function, they have avoided making any changes to the kernel at all.
ESRI's Spatial Data Engine, which is designed to be supported through an SQL interface to a relational database system, is thus also a simulator. It might then reasonably be asked what are the relative merits of ESRI's SDE and Oracle's SDO. We give a brief analysis below. The Informix spatial data blade is wasted on SDE which, as a simulator, cannot make use of it in the primary filter step. But SDE could benefit from faster complex object retrieval in the secondary filter, according to the analysis given above.
Informix is, to our knowledge, the only major database vendor which has decided to solve the problem the only way it really can be solved: by building a totally new system. Although they have suffered severe commercial setbacks and customer loss of confidence this year, Informix's problems are more attributable to marketing errors than technical failures. The new Informix Universal Server, freed from the legacy problems which Oracle and others still suffer, should easily outperform its rivals in spatial data handling. We expect that users will soon recognize this, and anticipate a rapid turn-around in Informix's fortunes. That is not to say, however, that the approach towards spatial data handling which Informix has inherited from Illustra is the best possible. In fact we consider that it has serious deficiencies.
Oracle Spatial Data Option (SDO)/Oracle 8 Spatial Data Cartridge
Oracle SDO was released in Oracle version 7.3 and replaces
Oracle 7MD released in April 1995. Despite its renaming, Oracle 8
Spatial Data Cartridge appears not to be different in any significant
respects from SDO, and so our references to SDO below stand for either.
We had some difficulty in locating a white paper on Oracle 8 Spatial Data
Cartridge from Oracle's web site in the US, but eventually tracked
it down further afield:
http://www.oracle.com.sg/st/o8collateral/html/xsdotwp3.html.
The design of Oracle 7MD was based on an approach to spatial data
management developed by the Canadian Hydrography Service. Perhaps
coincidentally, however, the design of both Oracle 7MD and SDO are
very close to an approach proposed by Orenstein in 1986. The
space-filling curve which is the basis of their mapping from n
dimensions to 1 dimension goes back much further - to Peano in 1890.
Our own approach to multi-dimensional indexing, which also relies
on Peano's work - though in a significantly different way - was
also first proposed in 1986.
Orenstein's motivation reveals at once the strength and weakness of the approach: it was to develop a viable means of handling spatial data in a relational database system, without having to introduce additional functionality into the kernel. That meant restricting indexing to B+-trees, and mapping all points and spatial extents on to this linear index. Such a mapping can be achieved with a space-filling curve, of which the two best known are due to Peano and Hilbert. A space-filling curve is a continuous curve which visits every point in the data space only once. The mapping from a point in the n-dimensional space to a point on the 1-dimensional line is extremely simple: if the coordinates of the n-dimensional point are expressed in binary form, then the corresponding point on the line is generated by interleaving the bits of each coordinate in cyclic order, from most to least significant. The result is a code which Oracle inherited from the Canadian Hydrography Service as an ``HHcode'' but which has previously been variously known as a ``Peano'' ``Morton'' or ``Z-order'' code. We prefer to maintain the attribution to its original inventor: Peano. Peano codes have a number of other interesting properties. In particular, if the domains of an n-dimensional data space are subjected to regular binary partitioning in cyclic order (i.e. are divided up bit-wise), the result is a regular grid of subspaces, each of which can be associated with a unique Peano code. For each further (cyclic) division of one of these subspaces, the associated Peano code extends by one bit. Thus every subspace which encloses another generated in the same way has an associated Peano code which is a prefix of that of the subspace(s) which it encloses. Quad-trees actually use the same encoding to identify subspaces. Following GIS nomenclature, SDO refers to these subspaces as tiles. With this representation, the primary filter step of a spatial query becomes, in principle at least, very simple. The extent of each spatial object is associated with a set of tiles which just completely covers it. The tiles don't all have to be the same size: in fact the aim is to cover the object to a predetermined accuracy with as few tiles as possible. (The precise algorithm which SDO uses for choosing the largest and smallest tile sizes for a given object cover is not specified in the white paper). A tile cover is also computed for the spatial query window. The primary filter query then reduces to finding those objects which have cover tiles in common with those of the query cover. The precise relationship depends on the form of the spatial query: containment, intersection or enclosure. For example, for an object to be completely or partially enclosed within the query window (an intersection query), the query cover and object cover must have at least one tile in common. More strictly, there must be at least one tile in the query cover which is identical with, or encloses, or is enclosed by, a tile in the object cover (i.e. either their Peano codes are identical, or one code is a prefix of the other). This constraint does not of course guarantee intersection: the secondary filter is then required to check the actual boundary of the candidate object with that of the query window.
In principle this seems a nice approach, and we consider it is probably the best that can be done if the database kernel cannot be modified. But the SDO implementation illustrates both the severe handicap under which it operates, and the distinction between simulation and native implementation. In a native implementation, there would be a relation of object instances (maybe normalized into more than one relation, as in the polygon example above), and an index pointing directly to those object instances. If the index were able to represent the spatial proximity of one object with another, then the index tree would have to directly represent a recursive partitioning of the data space, and the clustering of the object instances in the data pages would reflect this. In the SDO simulation, however, there is a second ordinary relation, which represents the association between objects and their cover tiles (i.e. Peano codes), and it is this relation which is then indexed by a one-dimensional B+-tree. Worse, being at the relational interface level., this organization is not hidden from the user, who is even responsible for maintaining it. The user then has to directly pose SQL queries in terms of tiles. This is completely against the spirit of SQL, which is to maintain independence from both the physical and logical organization of the data model. Efficient query execution must also be severely compromised, because internal steps of the query are forced above the SQL level.
Informix/Illustra R*-trees
Illustra pioneered the commercial exploitation of object-relational
database architecture, and the idea of 'data blades' i.e. a
flexible kernel which could accommodate integrated support for
new data types by the use of plug-ins. This idea is very attractive
in principle, but we have strong reservations about its real practical
viability. In particular, it is hard to see how queries involving new
data types can be optimized without substantial modifications to the
optimizer itself. There is no doubt, however, that the creation of a
completely new database system allowed the designers of Illustra a
completely free hand, without any legacy concerns. One of the most
successful aspects of Illustra - if not the most successful - was
its incorporation into the kernel of a spatial data blade based on
the R*-tree. This made it of great potential interest to the
implementors of the Alexandria digital library (ADL).
Illustra hardly had a long enough life of its own to be able to fairly evaluate the design and implementation of its spatial data handling. It was however used (and is still being used at the time of writing) to support the spatial querying aspects of ADL. Despite close support from the Illustra engineering team, it has to be said that there were serious implementation problems for almost a year: the R*-tree index simply did not work for ADL record sets greater than about three million. With Illustra's acquisition by Informix, we could not expect much further development support from the Illustra team. We have recently taken delivery of a DEC Alpha implementation of the new Informix Universal Server, and look forward to testing its spatial data blade - inherited, at least in principle, from Illustra, and using an R*-tree. The main advantage of Informix/Illustra's approach to spatial data handling is that the R*-tree is a true spatial index method, not a simulator. Thus, in contrast to Oracle SDO, the user is able to express spatial queries directly at the SQL level, and is not forced to consider implementation concepts like cover tiles. There is also no need to perform relational operations on intermediate cover tile mappings between the object base relation and the index, which so penalizes the performance of Oracle SDO.
As previously noted, the use of cover tiles is attractive in principle, because it allows the covers of objects to be represented much more accurately than can be achieved by a minimum bounding box as used in the R-tree. However, it may conversely be argued that it is a mistake to attempt to achieve great cover accuracy for what is only the primary filter step. The more tiles, the greater the complexity of the algorithm to check for query window overlap. The minimum bounding box is effectively a single tile. There seems at least some anecdotal evidence to support the latter argument: the performance of SDO is said to degrade sharply as the accuracy of the cover -- and the number of tiles - increases. Despite the evident advantages of the R*-tree, we do not view it as the perfect solution to spatial indexing problems. Although the R*-tree is a balanced grow and post tree like the B-tree, it lacks one of the B-tree's most fundamental and important properties: a B-tree can perform an exact-match query in a time logarithmic in the number of indexed objects. An R-tree or R*-tree cannot: in fact it cannot give any guaranteed upper limit on the time taken to perform an exact-match query, short of searching the entire file in the worst case. For classical, batch-oriented GIS applications this may be of no great practical importance. But GIS is now literally taking off: large spatial databases are becoming part of navigation systems in all forms of transport. These systems must perform in real time under circumstances where safety is of paramount importance. This requires accurate performance prediction and index structures which have absolutely guaranteed worst-case characteristics.
A second reservation about R*-trees is that they do not scale well to data spaces of higher dimension than two. This is not because the number of coordinates (i.e. 2n) of each minimum bounding box increases with the number of dimensions n (since this is only linear in n) but because of the complexity of the partitioning algorithm. Intuitively it is easy to appreciate that it becomes more difficult to find the best way to divide a box of objects into two separate boxes, with as little overlap between them as possible, as the number of dimensions increases.
Why does this matter? Again, for the support of classical GIS applications, it is of little practical importance. But applications requiring spatial point and object index support are no longer limited to GIS: they now include the whole field of data model visualization, in a host of contexts: for example, data mining. Although only three dimensions can be displayed directly in pictorial form, data mining visualization tools now regularly provide additional sliders etc. to allow the user to study data relationships in more than three dimensions. It is a general accepted fact that most of us can absorb up to seven dimensions of simultaneously presented information. Indexes must therefore be able to support at least this number of dimensions efficiently.
Finally, although R*-trees can support points as well as spatial extents, the inclusion of points is very cumbersome, since they are represented as degenerate minimum bounding boxes i.e. two pairs of identical coordinates. This overhead obviously increases in higher dimensions.
ESRI Spatial Data Engine (SDE)
As explained above, ESRI Spatial Data Engine is a simulator,
like Oracle SDO. It also has to be said that it is a much cruder
simulator than SDO. It operates very much on the same principles,
with primary and secondary filter steps and tiles to form spatial
object covers. The tiles are, however of a uniform size which must
be preset by the user. Clearly this is a much less flexible and
effective cover representation than that of either SDO or
the R*-tree, since the tile size does not relate in any way to
the size of the objects. To mitigate this problem, SDE allows
up to three parallel indexes, each with a different tile size.
Each object is allocated to the index whose tile size most closely
matches the size of the object.
Such a representation may well be adequate for spatial data extents
which tend all to be the same size. In GIS there are many examples
of such cases: county boundaries, population census tiles etc. But
there is no escaping that the SDE design is very limited and limiting.
Its real attraction cannot lie in its efficiency. It does however offer
ARC/INFO users a package by which they can extend their use of a
standard relational database to store their spatial data as well as
their feature data (i.e. the non-spatial attributes of spatial data).
Abstracts of Published and Submitted Articles
This paper presents a summary of some of the work-in-progress within the Alexandria Digital Library Project. In particular, we present scalable methods of locating information at different levels within a distributed digital library environment. Starting at the high level, we show how queries can be routed to appropriate information sources. At a given source, efficient query processing is supported by using materialized views and multidimensional index structures. Finally, we propose solutions to the problem of storage and retrieval of large objects on secondary and tertiary storage.
Abstract as above.
Pharos is a scalable distributed architecture for locating heterogeneous information sources. The system incorporates a hierarchical metadata structure into a multi-level retrieval system. Queries are resolved through an iterative decision-making process. The first step retrieves coarse-grain metadata, about all sources, stored on local, massively replicated, high-level servers. Further steps retrieve more detailed metadata, about a greatly reduced set of sources, stored on remote, sparsely replicated, topic-based mid-level servers. We present results of a simulation which indicate the feasibility of the architecture. We describe the structure, distribution, and retrieval of the metadatain Pharos to enable users to locate desirable information sources overthe Internet.
Information retrieval over the Internet increasingly requires the filtering of thousands of heterogeneous information sources. Important sources of information include not only traditional databases with structured data and queries, but also increasing numbers of non-traditional, semi- or un-structured collections such as Web sites, FTP archives, etc. As the number and variability of sources increases, new ways of automatically summarizing, discovering, and selecting collections relevant to a user's query are needed. One such method involves the use of classification schemes, such as the Library of Congress Classification (LCC), within which a collection may be represented based on its content, irrespective of the structure of the actual data or documents. For such a system to be useful in a large-scale distributed environment, it must be easy to use for both collection managers and users. As a result, it must be possible to classify documents automatically within a classification scheme. Furthermore, there must be a straightforward and intuitive interface with which the user may use the scheme to assist in information retrieval (IR). We are currently experimenting with newsgroups as collections. We have built an initial prototype which automatically classifies and summarizes newsgroups within the LCC. The prototype uses electronic library catalog records as a `training set' and Latent Semantic Indexing (LSI) for IR. This work is extensible to other types of classification, including geographical, temporal, and image feature.
Information retrieval over the Internet increasingly requires the filtering of thousands of information sources. As the number of sources increases, new ways of automatically summarizing, discovering, and selecting sources relevant to a user's query are needed. Pharos is a highly scalable distributed architecture for locating heterogeneous information sources. Its design is hierarchical, thus allowing it to scale well as the number of information sources increases. We demonstrate the feasibility of the Pharos architecture using 2500 Usenet newsgroups as separate collections. Each newsgroup is summarized via automated Library of Congress classification. We show that using Pharos as an intermediate retrieval mechanism provides acceptable accuracy of source selection compared to selecting sources using complete classification information, while maintaining reasonable scalability.
In this paper we develop a data integration approach for
the efficient evaluation of queries over autonomous source
databases. The approach is based on some novel applications and
extensions of constraint databases techniques. We assume the
existence of a global database schema. The contents of each
data source are described using a set of constraint tuples
over the global schema; each such tuple indicates possible
contributions from the source. The ``source description catalog''
(SDC) of a global relation consists of its associated constraint
tuples. Such a way of description is more advantageous, by
allowing flexible addition and modification of sources, than
approaches such as Tsimmis where the correspondence between
sources and the global schema is compiled into the mediators.
In our framework, to evaluate a conjunctive query over the
global schema, a plan generator first identifies relevant
data sources by ``evaluating'' the query against the SDCs
using techniques of constraint query evaluation; it then
formulates an evaluation plan, consisting of some specialized
queries over different paths. The evaluation of a query
associated with a path is done by a sequence of partial
evaluations at data sources along the path, similar to
side-ways information passing of Datalog; the partially
evaluated queries travel along their associated paths.
Our SDC-based query planning is more efficient than
approaches such as Information Manifold and SIMS
by avoiding their NP-complete query rewriting process.
We can achieve further optimization
using techniques such as emptiness test.
Presentations:lexandria Digital Library Project at UC Santa Barbara has been building an information retrieval system for geographically-referenced information and datasets. To meet these requirements, we have designed a distributed Data Store to store its holdings. The library's map, image and geographical data are viewed as a collection of objects with evolving roles. Developed in the Java programming language and the HORB distributed object system, the Data Store manages these objects for flexible and scalable processing. To implement the Data Store we provide a messaging layer that allows applications to distribute processing between the Data Store and the local host. We define a data model for Data Store repositories that provide Client access to Data Store objects. We finally provide support for specialized views of these Data Store items.
We describe the design and implementation of StratOSphere, a framework which unifies distributed objects and mobile code applications. We begin by first examining different mobile code paradigms that distribute processing of code and data resource components across a network. After analyzing these paradigms, and presenting a lattice of functionality, we then develop a layered architecture for StratOSphere, incorporating higher levels of mobility and interoperability at each successive layer. In our design, we provide an object model that permits objects to migrate to different sites, select among different method implementations, and provide new methods and behavior. We describe how we build new semantics in each software layer, and finally, we present sample objects developed for StratOSphere.
Multi-dimensional range searching has important applications in
several fields including spatial, image and text databases.
Several data structures using linear and non-linear storage space
have been proposed in database and computational geometry
literature. These structures support poly-logarithmic range
query time using 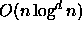 storage space for n
d-dimensional point data.
Using linear-space, query times of
storage space for n
d-dimensional point data.
Using linear-space, query times of 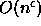 for any
for any 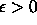 can be achieved by replicating each data
item at least
can be achieved by replicating each data
item at least 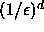 times. Such large storage-space
structures may not be feasible for
several databases. In this paper,
we examine the complexity of range searching when data items
are not replicated.
Such non-replicating structures
achieve low storage costs and fast update times due to lack of
multiple copies. Examples of non-replicating structures include
R-trees, Bang files,
quad trees and k-d trees.
In this paper, we first obtain a lower bound for range searching
in such non-replicating index structures.
Assuming a simple tree structure model of an index,
we prove that the worst-case query time for a query retrieving
t out of n data items is
times. Such large storage-space
structures may not be feasible for
several databases. In this paper,
we examine the complexity of range searching when data items
are not replicated.
Such non-replicating structures
achieve low storage costs and fast update times due to lack of
multiple copies. Examples of non-replicating structures include
R-trees, Bang files,
quad trees and k-d trees.
In this paper, we first obtain a lower bound for range searching
in such non-replicating index structures.
Assuming a simple tree structure model of an index,
we prove that the worst-case query time for a query retrieving
t out of n data items is  ,
where d is the data dimensionality and
b is the capacity of index nodes.
We then propose a new index structure, called the O-tree, that
achieves this query time in dynamic environments.
Updates are supported in
,
where d is the data dimensionality and
b is the capacity of index nodes.
We then propose a new index structure, called the O-tree, that
achieves this query time in dynamic environments.
Updates are supported in 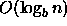 amortized time and exact
match queries in
amortized time and exact
match queries in 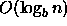 worst-case time. This structure
improves the query time of the best known non-replicating
structure, the divided k-d tree, and is optimal for
both queries and updates in non-replicating tree structures.
In contrast to these lower and upper bounds, we prove that
index structures such as R-trees and Bang files exhibit
a worst-case complexity of
worst-case time. This structure
improves the query time of the best known non-replicating
structure, the divided k-d tree, and is optimal for
both queries and updates in non-replicating tree structures.
In contrast to these lower and upper bounds, we prove that
index structures such as R-trees and Bang files exhibit
a worst-case complexity of 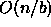 .
.
In this paper, we consider the problem of dynamic range searching
in linear-space index structures. We propose a new dynamic
structure that combines Bentley's multilevel range
structure with Overmars' dynamization techniques. This structure
achieves 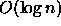 time complexity for updates and
time complexity for updates and
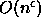 time complexity for queries, for
any
time complexity for queries, for
any 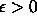 . This result is an improvement over
the static-to-dynamic transformations of Bentley's structure,
which yield an update time of
. This result is an improvement over
the static-to-dynamic transformations of Bentley's structure,
which yield an update time of  and a query time
of
and a query time
of  for any
for any 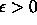 .
.
Databases are increasingly being used to store multi-media objects
such as maps, images, audio and video. Storage and retrieval
of these objects is accomplished using multi-dimensional index
structures such as R
 -trees and SS-trees.
As dimensionality increases, query performance in these index
structures degrades. This phenomenon, generally referred to as
the dimensionality curse, can be circumvented by reducing the
dimensionality of the data. Such a reduction is however
accompanied by a loss of precision of query results.
Current techniques such as QBIC use SVD transform-based
dimensionality reduction to ensure high query precision.
The drawback of this approach is that SVD is
expensive to compute, and therefore not readily applicable to
dynamic databases. In this paper, we propose novel techniques
for performing SVD-based dimensionality reduction in dynamic
databases. When the data distribution changes considerably
so as to degrade query precision, we recompute the SVD transform
and incorporate it in the existing index structure. For
recomputing the SVD-transform, we propose a novel technique that
uses aggregate data from the existing index rather
than the entire data. This technique reduces the SVD-computation
time without compromising query precision. We then explore
efficient ways to incorporate the recomputed SVD-transform in the
existing index structure without degrading subsequent query
response times. These techniques reduce the computation time by a
factor of 20 in experiments on color and texture image vectors.
The error due to approximate computation of SVD is less than 10%.
-trees and SS-trees.
As dimensionality increases, query performance in these index
structures degrades. This phenomenon, generally referred to as
the dimensionality curse, can be circumvented by reducing the
dimensionality of the data. Such a reduction is however
accompanied by a loss of precision of query results.
Current techniques such as QBIC use SVD transform-based
dimensionality reduction to ensure high query precision.
The drawback of this approach is that SVD is
expensive to compute, and therefore not readily applicable to
dynamic databases. In this paper, we propose novel techniques
for performing SVD-based dimensionality reduction in dynamic
databases. When the data distribution changes considerably
so as to degrade query precision, we recompute the SVD transform
and incorporate it in the existing index structure. For
recomputing the SVD-transform, we propose a novel technique that
uses aggregate data from the existing index rather
than the entire data. This technique reduces the SVD-computation
time without compromising query precision. We then explore
efficient ways to incorporate the recomputed SVD-transform in the
existing index structure without degrading subsequent query
response times. These techniques reduce the computation time by a
factor of 20 in experiments on color and texture image vectors.
The error due to approximate computation of SVD is less than 10%.
Multi-dimensional index structures such as R-trees enable fast searching in high-dimensional spaces. They differ from uni-dimensional structures in the following aspects: (1) index regions in the tree may be modified during ordinary insert and delete operations, and (2) node splits during inserts are quite expensive. Both these characteristics may lead to reduced concurrency of update and query operations. In this paper, we examine how to achieve high concurrency for multi-dimensional structures. First, we develop a new technique for efficiently handling index region modifications. Then, we extend it to reduce/eliminate query blocking overheads during node-splits. We examine two variants of this extended scheme -- one that reduces the blocking overhead for queries, and another that completely eliminates it. Experiments on image data on a shared-memory multi-processor show that these schemes achieve up to 2 times higher throughput than existing techniques, and scale well with the number of processors.
Non-uniformity in data extents is a general characteristic of
spatial data. Indexing such non-uniform data using conventional
spatial index structures such as R -trees is inefficient for
two reasons: (1) The non-uniformity increases the likelihood of
overlapping index entries, and, (2) clustering of non-uniform
data is likely to index more dead space than clustering
of uniform data. To reduce the impact of these anomalies, we
propose a new scheme that promotes data objects to higher levels
in tree-based index structures. We examine two criteria for
promotion of data objects and evaluate their relative merits
using an R
-trees is inefficient for
two reasons: (1) The non-uniformity increases the likelihood of
overlapping index entries, and, (2) clustering of non-uniform
data is likely to index more dead space than clustering
of uniform data. To reduce the impact of these anomalies, we
propose a new scheme that promotes data objects to higher levels
in tree-based index structures. We examine two criteria for
promotion of data objects and evaluate their relative merits
using an R -tree. In experiments on cartographic data, we
observe that our promotion criteria yield upto 45% improvement
in query performance for an R
-tree. In experiments on cartographic data, we
observe that our promotion criteria yield upto 45% improvement
in query performance for an R -tree.
-tree.
Indexing multidimensional data is inherently complex leading to slow query processing. This behavior becomes more pronounced with the increase in database size and/or number of dimensions. In this paper, we address this issue by processing an index structure in parallel. First, we study different ways of partitioning an index structure. We then propose efficient algorithms for processing each query in parallel on the index structure. Using these strategies, we parallelized two multidimensional index structures -- R* and LIB and evaluated the performance gains for the Gazetteer and the Catalog data of the Alexandria Digital Library on the Meiko CS-2.
Efficient evaluation of user queries is very important and critical in database applications involving very large amount of data. In these applications, especially the ones where query answers are expected in real time, performance of query evaluation in a DBMS may be poor; often in such cases, query performance is extremely sensitive to the structure of the database schema. For example, if a query joins several very large relations (in terms of the number of tuples), the joins may be very expensive even with efficient algorithms. On the other hand, if such joins are ``materialized'', i.e. precomputed, stored, and properly indexed, the joins can be avoided at the query evaluation time. In our experiments, the performance improvement by join elimination is significant. Based on the analysis of several large operational database application systems and experimental results, we argue that normalized database schemas should remain for the sake of semantic integrity (upon updates) and that some joins can be materialized to improve query performance. In this paper, we develop techniques to (1) select joins to be materialized based on query statistics and ER diagrams, (2) generate materialized joins with tags to avoid duplicate removal, and (3) translate queries on the base relations to equivalent ones using materialized joins. We also describe an architecture to embed this performance tuning method into existing application systems and a prototype implemented within the Alexandria Digital Library system. We report experimental results on this prototype.
A current trend in database architecture is to provide 'data blades' or 'data cartridges' as 'plug-in' indexing methods to support new data types. The research project which gave rise to this paper aims to test the practicality of a diametrically opposite approach: the development of a new, generic indexing technology i.e. a single indexing technique capable of supporting a wide range of data types. We believe that BANG indexing [Fre87] is now a viable candidate for such a technology, as a result of a series of extensions and refinements, and fundamental improvements in worst-case characteristics made possible by recent theoretical advances. The task is therefore to test whether this single generalized technique can match the performance of several other specialized methods.
Various proposals have been made for declustering two-dimensionally tiled data on multiple I/O devices. Recently, it was shown that strictly optimal solutions only exist under very restrictive conditions on the tiling of the two-dimensional space or for very few I/O devices. In this paper we explore allocation methods where no strictly optimal solution exists. We propose a general class of allocation methods, referred to as cyclic declustering methods, and show that many existing methods are instances of this class. As a result, various seemingly ad hoc and unrelated methods are presented in a single framework. Furthermore, the framework is used to develop new allocation methods that give better performance than any previous method and that approach the best feasible performance.
With rapid advances in computer and communication technologies, there is an increasing demand to build and maintain large image repositories. In order to reduce the demands on I/O and network resources, multiresolution representations are being proposed for the storage organization of images. Image decomposition techniques such as wavelets can be used to provide these multiresolution images. The original image is represented by several coefficients, one of them with visual similarity to the original image, but at a lower resolution. These visually similar coefficients can be thought of as thumbnails or icons of the original image. This paper addresses the problem of storing these multiresolution coefficients on disks so that thumbnail browsing as well as image reconstruction can be performed efficiently. Several strategies are evaluated to store the image coefficients on parallel disks. These strategies can be classified into two broad classes depending on whether the access pattern of the images is used in the placement. Disk simulation is used to evaluate the performance of these strategies. Simulation results are validated with results from experiments with real disks and are found to be in good agreement. The results indicate that significant performance improvements can be achieved with as few as four disks by placing image coefficients based upon browsing access patterns.
With the recent improvements in network and processor speeds many data intensive applications such as digital libraries, data mining, etc., have become more feasible than ever before. The only practical solution for their enormous storage needs is tertiary storage. Automated access to tertiary storage is made possible through tape and optical disk robotic libraries. The slow speeds of operation of the drives and library robotics imply large access times. This high access latency and the bursty nature of I/O traffic result in the accumulation of I/O requests at the storage library. We study the problem of scheduling these requests to improve performance. We focus on scheduling policies that process all requests on a loaded medium before unloading it. For single drive settings an efficient algorithm that produces optimal schedules is developed. For multiple drives the problem is shown to be NP-Complete. Efficient and effective heuristics are presented for the multiple drive case. The scheduling policies developed achieve significant performance gains over more naive policies. The algorithms developed are simple to implement and are not restrictive. The study is general enough to be applicable to any storage library handling removable media, such as tapes and optical disks.
As databases increasingly integrate non-textual information it is becoming necessary to support efficient similarity searching in addition to range searching. Recently, declustering techniques have been proposed for improving the performance of similarity searches through parallel I/O. In this paper, we propose a new scheme which provides good declustering for similarity searching. In particular, it does global declustering as opposed to local declustering, exploits the availability of extra disks and does not limit the partitioning of the data space. Our technique is based upon the cyclic declustering schemes which were developed for range and partial match queries. We establish, in general, that cyclic declustering techniques outperform previously proposed techniques.
Many scientific and engineering applications process large multidimensional datasets. An important access pattern for these applications is the retrieval of data corresponding to ranges of values in multiple dimensions. Performance of these accesses is limited by the poor performance of magnetic disks, largely due to high disk latencies. Tiling the multidimensional data space and exploiting parallel I/O from multiple disks is an effective technique for improving performance. The gains from parallelism are chiefly determined by the distribution of the tiles across the parallel disks such that as many accesses as possible are maximally parallelised. Several schemes for declustering multidimensional data to improve the performance of range queries have been proposed in the literature. We extend the class of cyclic schemes which have been developed earlier for two-dimensional data to multiple dimensions. We begin by establishing some important properties of these allocation schemes. Based upon these properties, we identify techniques for reducing the search space for determining good declustering schemes within the class of cyclic schemes. Through experimental evaluation, we establish that the cyclic schemes are superior to other declustering schemes both in terms of the degree of parallelism achieved and robustness to variations in parameters. In particular, we show that the exhaustive cyclic scheme gives better performance than the state-of-the-art scheme for declustering multidimensional data for range queries.
This report summarizes current state of the art in tertiary storage systems. We begin with a comprehensive discussion of magnetic tape and optical storage technologies. This is followed by a classification of commercial products based on their performance characteristics. Our analysis of product data indicates that in contrast to disk technology, tertiary storage products have significant variablility in terms of data transfer rates as well as other performance figures. We then summarize efforts in the areas of operating systems, databases and advanced applications to integrate tertiary storage. We point out that different assumptions about the underlying technology result in entirely different algorithms and system design. We conclude the report with a speculation of future trends.